A Dynamic, Self Supervised, Large Scale AudioVisual Dataset for Stuttered Speech
Abstract
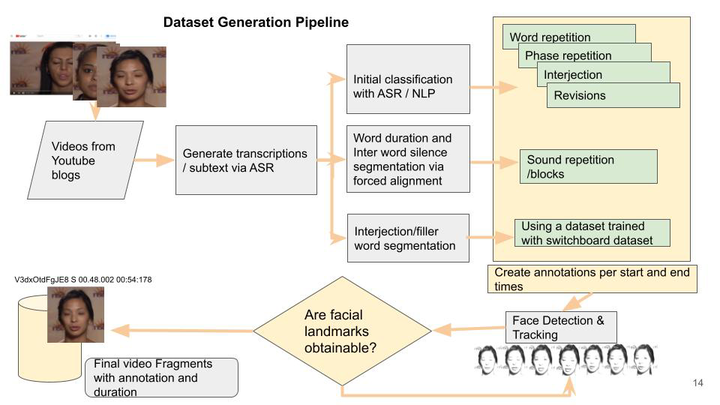
Stuttering affects at least 1% of the world population. It is caused by irregular disruptions in speech production. These interruptions occur in various forms and frequencies. Repetition of words or parts of words, prolongations, or blocks in getting the words out are the most common ones. Accurate detection and classification of stuttering would be important in the assessment of severity for speech therapy. Furthermore, real time detection might create many new possibilities to facilitate reconstruction into fluent speech. Such an interface could help people to utilize voice-based interfaces like Apple Siri and Google Assistant, or to make (video) phone calls more fluent by delayed delivery. In this paper we present the first expandable audio-visual database of stuttered speech. We explore an end-to-end, real-time, multi-modal model for detection and classification of stuttered blocks in unbound speech. We also make use of video signals since acoustic signals cannot be produced immediately. We use multiple modalities as acoustic signals together with secondary characteristics exhibited in visual signals will permit an increased accuracy of detection.