Abstract
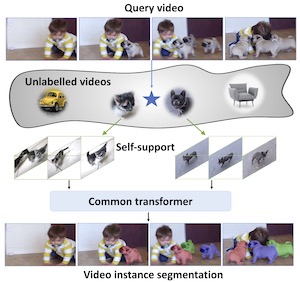
The goal of this paper is to bypass the need for labelled examples in few-shot video understanding at run time. While proven effective, in many practical video settings even labelling a few examples appears unrealistic. This is especially true as the level of details in spatio-temporal video understanding and with it, the complexity of annotations continues to increase. Rather than performing few-shot learning with a human oracle to provide a few densely labelled support videos, we propose to automatically learn to find appropriate support videos given a query. We call this self-shot learning and we outline a simple self-supervised learning method to generate an embedding space well-suited for unsupervised retrieval of relevant samples. To showcase this novel setting, we tackle, for the first time, video instance segmentation in a self-shot (and few-shot) setting, where the goal is to segment instances at the pixel-level across the spatial and temporal domains. We provide strong baseline performances that utilize a novel transformer-based model and show that self-shot learning can even surpass few-shot and can be positively combined for further performance gains. Experiments on new benchmarks show that our approach achieves strong performance, is competitive to oracle support in some settings, scales to large unlabelled video collections, and can be combined in a semi-supervised setting.