Multi-Task Edge Prediction in Temporally-Dynamic Video Graphs
Abstract
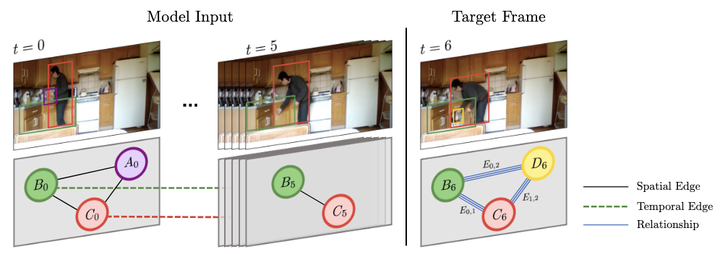
Graph neural networks have shown to learn effective node representations, enabling node-, link-, and graph-level inference. Conventional graph networks assume static relations between nodes, while relations between entities in a video often evolve over time, with nodes entering and exiting dynamically. In such temporally-dynamic graphs, a core problem is inferring the future state of spatio-temporal edges, which can constitute multiple types of relations. To address this problem, we propose MTD-GNN, a graph network for predicting temporally-dynamic edges for multiple types of relations. We propose a factorized spatio-temporal graph attention layer to learn dynamic node representations and present a multi-task edge prediction loss that models multiple relations simultaneously. The proposed architecture operates on top of scene graphs that we obtain from videos through object detection and spatio-temporal linking. Experimental evaluations on ActionGenome and CLEVRER show that modeling multiple relations in our temporally-dynamic graph network can be mutually beneficial, outperforming existing static and spatio-temporal graph neural networks, as well as state-of-the-art predicate classification methods.