ELLIS unit Amsterdam, with the support of Qualcomm Technologies, is able to provide travel grants for students to present their papers at top-tier ML or AI conferences. The travel grant not only facilitates academic exposure but also fosters cross-cultural exchange, empowering students with diverse perspectives and broadening their horizons in the ever-evolving fields of machine learning and artificial intelligence.
We interviewed 4 recipients and present an overview of their research here.
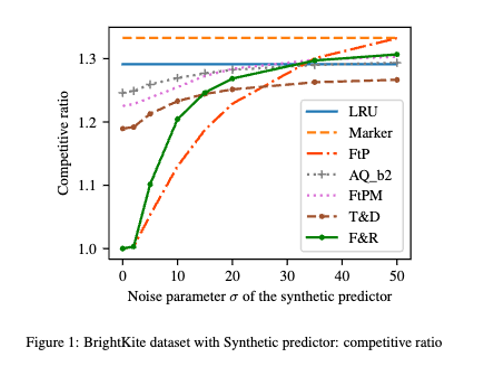
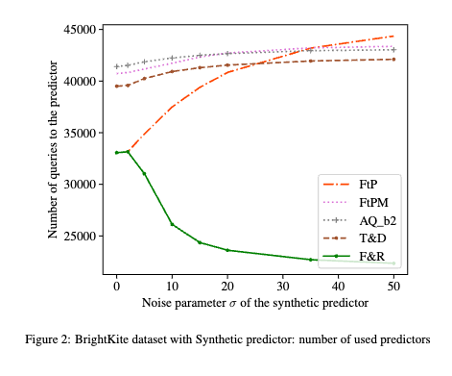
Title of the paper: Algorithms for Caching and MTS with reduced number of predictions
Authors: Karim Abdel Sadek, Marek Eliáš
Conference: ICLR 2024 (International Conference on Learning Representations 2024), Vienna
Summary:
ML-augmented algorithms utilize predictions to achieve performance beyond their worst-case bounds. Producing these predictions might be a costly operation – this motivated Im et al. [1] to introduce the study of algorithms which use predictions parsimoniously. In the paper we design parsimonious algorithms for caching and MTS with action predictions, proposed by Antoniadis et al. [2], focusing on the parameters of consistency (performance with perfect predictions) and smoothness (dependence of their performance on prediction error). Our algorithm for caching ((Follower&Robust) ) is 1-consistent, robust, and its smoothness deteriorates with decreasing number of available predictions. We propose an algorithm for general MTS whose consistency and smoothness both scale linearly with the decreasing number of predictions. Without restriction on the number of available predictions, both algorithms match the earlier guarantees achieved by Antoniadis et al. [2].
References: [1] S. Im, R. Kumar, A. Petety, and M. Purohit. Parsimonious learning-augmented caching. In ICML, 2022 ; [2] A. Antoniadis, C. Coester, M. Eliáš, A. Polak, and B. Simon. Online metric algorithms with untrusted predictions. ACM Trans. Algorithms, 19(2), apr 2023. ISSN 1549-6325. doi: 10.1145/3582689. URL https://doi.org/10.1145/3582689.
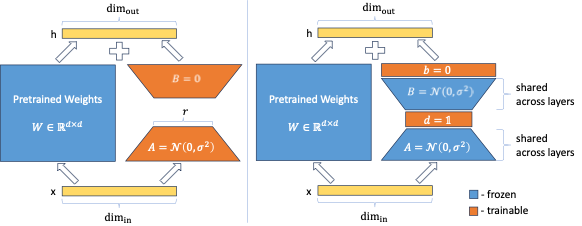
Title of the paper: VeRA: Vector-based Random Matrix Adaptation
Authors: Dawid J. Kopiczko, Tijmen Blankevoort, Yuki M. Asano
Conference: ICLR 2024 (International Conference on Learning Representations 2024), Vienna
Summary:
Low-rank adapation (LoRA) is a popular method that reduces the number of trainable parameters when finetuning large language models, but still faces acute storage challenges when scaling to even larger models or deploying numerous per-user or per-task adapted models. In this work, we present Vector-based Random Matrix Adaptation (VeRA), which significantly reduces the number of trainable parameters compared to LoRA, yet maintains the same performance. It achieves this by using a single pair of low-rank matrices shared across all layers and learning small scaling vectors instead. We demonstrate its effectiveness on the GLUE and E2E benchmarks, image classification tasks, and show its application in instruction-tuning of 7B and 13B language models.
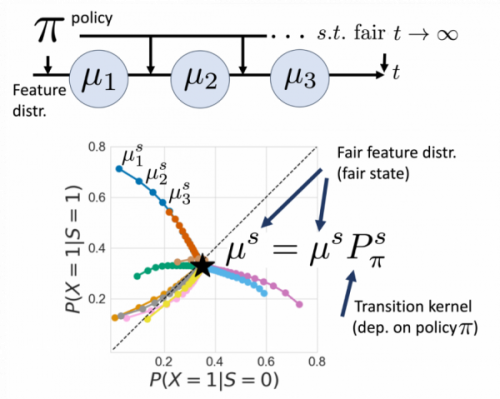
Title of the paper: Designing Long-term Group Fair Policies in Dynamical Systems
Authors: Miriam Rateike, Isabel Valera, Patrick Forré
Conference: ICLR 2024 (International Conference on Learning Representations 2024), Vienna
Summary:
Neglecting the effect that decisions have on individuals (and thus, on the underlying data distribution) when designing algorithmic decision-making policies may increase inequalities and unfairness in the long term—even if fairness considerations were taken into account in the policy design process. In this paper, we propose a novel framework for studying long-term group fairness in dynamical systems, in which current decisions may affect an individual’s features in the next step, and thus, future decisions. Specifically, our framework allows us to identify a time-independent policy {that converges}, if deployed, to the targeted fair stationary state of the system in the long-term, independently of the initial data distribution. We model the system dynamics with a time-homogeneous Markov chain and optimize the policy leveraging the Markov chain convergence theorem to ensure unique convergence. Our framework enables the utilization of historical temporal data to tackle challenges associated with delayed feedback when learning long-term fair policies in practice. Importantly, our framework shows that interventions on the data distribution (e.g., subsidies) can be used to achieve policy learning that is both short- and long-term fair. We provide examples of different targeted fair states of the system, encompassing a range of long-term goals for society and policymakers. In semi-synthetic simulations based on real-world datasets, we show how our approach facilitates identifying effective interventions for long-term fairness.
Title of the paper: Lie Group Decompositions for Equivariant Neural Networks
Authors: Mircea Mironenco, Patrick Forré
Conference: ICLR 2024 (International Conference on Learning Representations 2024), Vienna
Summary:
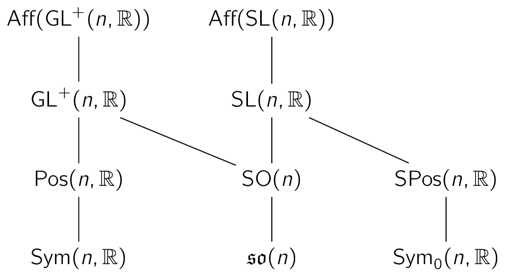
We present a framework that allows for the generalization of Group Equivariant Convolutions to arbitrary Lie groups. This research direction is promising since it allows for the modelling of symmetry groups beyond Euclidean geometry. Affine and projective geometry, respectively affine and homography transformations are ubiquitous within computer vision, robotics and computer graphics. Accounting for a larger degree of geometric variation given by these transformations has the promise of making (vision) architectures more robust to real-world data shifts.
We specifically address the problem of working with non-compact and non-abelian Lie groups, for which the group exponential is not surjective, and for which standard harmonic analysis tools cannot be employed straightforwardly. For such groups we present a procedure by which invariant integration with respect to their Haar measure can be done in a principled manner, allowing for an efficient numerical integration scheme to be realized. We then construct global parametrization maps which allow us to map elements back and forth between the Lie algebra and the group, addressing the non-surjectivity of the group exponential. Under this framework, we show how convolution kernels can be parametrized to build models equivariant with respect to affine transformations. We evaluate the robustness and out-of-distribution generalisation capability of our model on the standard affine-invariant benchmark image classification task, where we outperform all previous equivariant models as well as all Capsule Network proposals.