Feature-Supervised Action Modality Transfer
Abstract
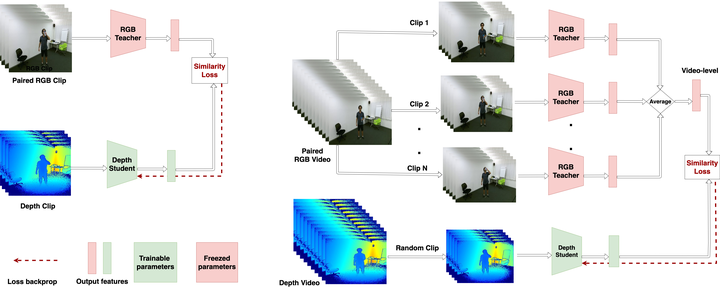
This paper strives for action recognition and detection in video modalities like RGB, depth maps or 3D-skeleton sequences when only limited modality-specific labeled examples are available. For the RGB, and derived optical-flow, modality many large-scale labeled datasets have been made available. They have become the de facto pre-training choice when recognizing or detecting new actions from RGB datasets that have limited amounts of labeled examples available. Unfortunately, large-scale labeled action datasets for other modalities are unavailable for pre-training. In this paper, our goal is to recognize actions from limited examples in non-RGB video modalities, by learning from large-scale labeled RGB data. To this end, we propose a two-step training process: (i) we extract action representation knowledge from an RGB-trained teacher network and adapt it to a non-RGB student network. (ii) we then fine-tune the transfer model with available labeled examples of the target modality. For the knowledge transfer we introduce feature-supervision strategies, which rely on unlabeled pairs of two modalities (the RGB and the target modality) to transfer feature-level representations from the teacher to the student network. Ablations and generalizations with two RGB source datasets and two non-RGB target datasets demonstrate that an optical-flow teacher provides better action transfer features than RGB for both depth maps and 3D-skeletons, even when evaluated on a different target domain, or for a different task. Compared to alternative cross-modal action transfer methods we show a good improvement in performance especially when labeled non-RGB examples to learn from are scarce.