Query by Activity Video in the Wild
Abstract
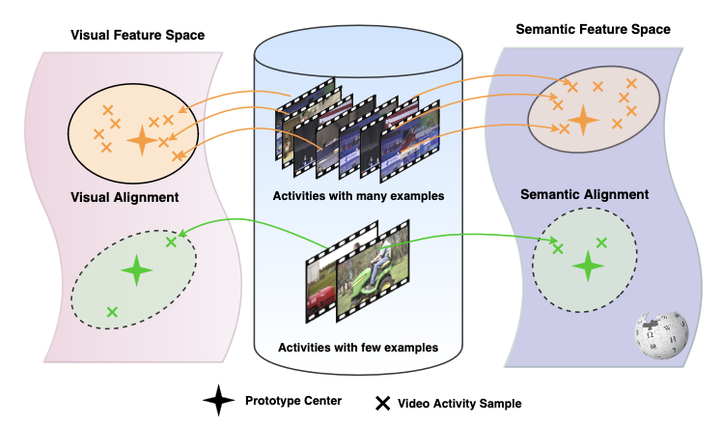
This paper considers retrieval of videos containing human activity from just a video query. In the literature, a common assumption is that all activities have sufficient labelled examples when learning an embedding for retrieval. However, this assumption does not hold in practice, as only a portion of activities have many examples, while other activities are only described by few examples. In this paper, we propose a visual-semantic embedding network that explicitly deals with the imbalanced scenario for activity retrieval. Our network contains two novel modules. The visual alignment module performs a global alignment between the input video and visual feature bank representations for all activities. The semantic module performs an alignment between the input video and semantic activity representations. By matching videos with both visual and semantic activity representations over all activities, we no longer ignore infrequent activities during retrieval. Experiments on a new imbalanced activity retrieval benchmark show the effectiveness of our proposal.