Universal Prototype Transport for Zero-Shot Action Recognition and Localization
Abstract
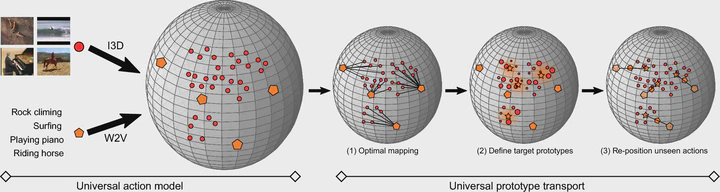
This work addresses the problem of recognizing action categories in videos when no training examples are available. The current state-of-the-art enables such a zero-shot recognition by learning universal mappings from videos to a semantic space, either trained on large-scale seen actions or on objects. While effective, we find that universal action and object mappings are biased to specific regions in the semantic space. These biases lead to a fundamental problem: many unseen action categories are simply never inferred during testing. For example on UCF-101, a quarter of the unseen actions are out of reach with a state-of-the-art universal action model. To that end, this paper introduces universal prototype transport for zero-shot action recognition. The main idea is to re-position the semantic prototypes of unseen actions by matching them to the distribution of all test videos. For universal action models, we propose to match distributions through a hyperspherical optimal transport from unseen action prototypes to the set of all projected test videos. The resulting transport couplings in turn determine the target prototype for each unseen action. Rather than directly using the target prototype as final result, we re-position unseen action prototypes along the geodesic spanned by the original and target prototypes as a form of semantic regularization. For universal object models, we outline a variant that defines target prototypes based on an optimal transport between unseen action prototypes and object prototypes. Empirically, we show that universal prototype transport diminishes the biased selection of unseen action prototypes and boosts both universal action and object models for zero-shot classification and spatio-temporal localization.