Localizing the Common Action Among a Few Videos
Abstract
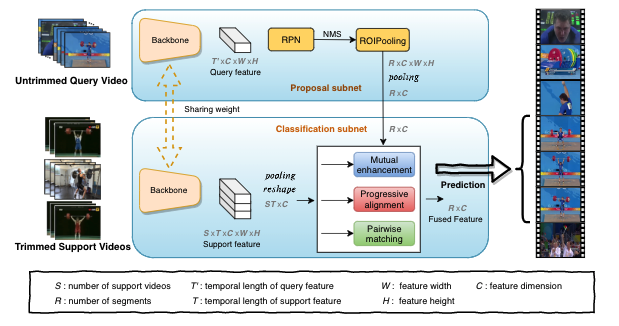
This paper strives to localize the temporal extent of an action in a long untrimmed video. Where existing work leverages many examples with their start, their ending, and/or the class of the action during training time, we propose few-shot common action localization. The start and end of an action in a long untrimmed video is determined based on just a hand-full of trimmed video examples containing the same action, without knowing their common class label. To address this task, we introduce a new 3D convolutional network architecture able to align representations from the support videos with the relevant query video segments. The network contains: ( extit{i}) a mutual enhancement module to simultaneously complement the representation of the few trimmed support videos and the untrimmed query video; ( extit{ii}) a progressive alignment module that iteratively fuses the support videos into the query branch; and ( extit{iii}) a pairwise matching module to weigh the importance of different support videos. Evaluation of few-shot common action localization in untrimmed videos containing a single or multiple action instances demonstrates the effectiveness and general applicability of our proposal.