Zero-Shot Action Recognition from Diverse Object-Scene Compositions
Abstract
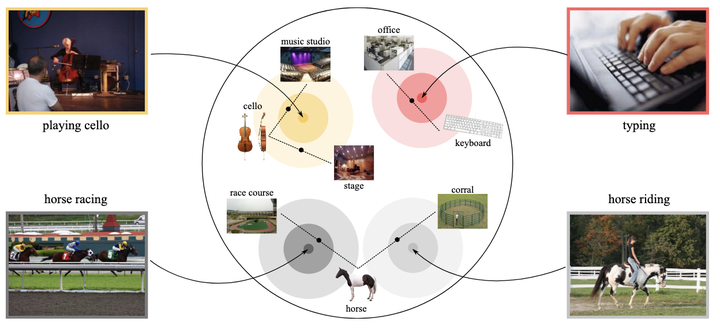
This paper investigates the problem of zero-shot action recognition, in the setting where no training videos with seen actions are available. For this challenging scenario, the current leading approach is to transfer knowledge from the image domain by recognizing objects in videos using pre-trained networks, followed by a semantic matching between objects and actions. Where objects provide a local view on the content in videos, in this work we also seek to include a global view of the scene in which actions occur. We find that scenes on their own are also capable of recognizing unseen actions, albeit more marginally than objects, and a direct combination of object-based and scene-based scores degrades the action recognition performance. To get the best out of objects and scenes, we propose to construct them as a Cartesian product of all possible compositions. We outline how to determine the likelihood of object-scene compositions in videos, as well as a semantic matching from object-scene compositions to actions that enforces diversity among the most relevant compositions for each action. While simple, our composition-based approach outperforms object-based approaches and even state-of-the-art zero-shot approaches that rely on large-scale video datasets with hundreds of seen actions for training and knowledge transfer.