ELLIS unit Amsterdam, with the support of Qualcomm Technologies, is able to provide travel grants for students to present their papers at top-tier ML or AI conferences. The travel grant not only facilitates academic exposure but also fosters cross-cultural exchange, empowering students with diverse perspectives and broadening their horizons in the ever-evolving fields of machine learning and artificial intelligence.
We interviewed 4 recipients and present an overview of their research here.
Karim Abdel Sadek
- Title of the paper: Algorithms for Caching and MTS with reduced number of predictions
- Authors: Karim Abdel Sadek, Marek Eliáš
- Conference: ICLR 2024 (International Conference on Learning Representations 2024), Vienna
- Open Review | Arxiv
Summary:
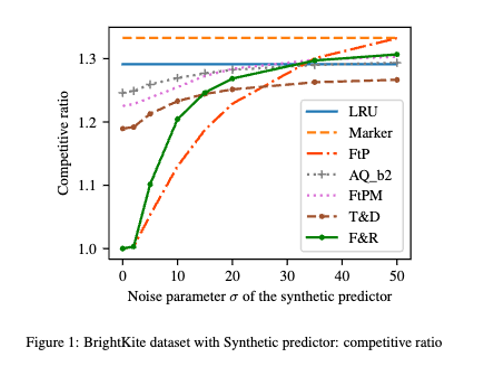
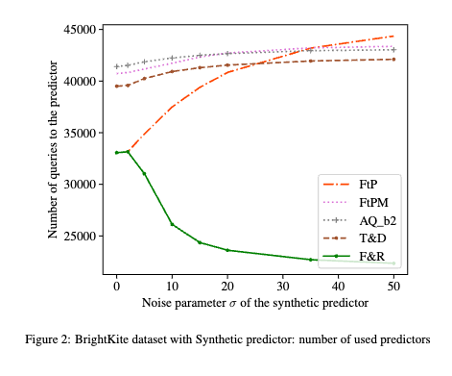
ML-augmented algorithms utilize predictions to achieve performance beyond their worst-case bounds. Producing these predictions might be a costly operation – this motivated Im et al. [1] to introduce the study of algorithms which use predictions parsimoniously. In the paper we design parsimonious algorithms for caching and MTS with action predictions, proposed by Antoniadis et al. [2], focusing on the parameters of consistency (performance with perfect predictions) and smoothness (dependence of their performance on prediction error). Our algorithm for caching ((Follower&Robust) ) is 1-consistent, robust, and its smoothness deteriorates with decreasing number of available predictions. We propose an algorithm for general MTS whose consistency and smoothness both scale linearly with the decreasing number of predictions. Without restriction on the number of available predictions, both algorithms match the earlier guarantees achieved by Antoniadis et al. [2].
References: [1] S. Im, R. Kumar, A. Petety, and M. Purohit. Parsimonious learning-augmented caching. In ICML, 2022 ; [2] A. Antoniadis, C. Coester, M. Eliáš, A. Polak, and B. Simon. Online metric algorithms with untrusted predictions. ACM Trans. Algorithms, 19(2), apr 2023. ISSN 1549-6325. doi: 10.1145/3582689. URL https://doi.org/10.1145/3582689.