The Amsterdam unit of the European Laboratory for Learning and Intelligent Systems– ELLIS Society network is proud to support the next generation of Machine Learning and Artificial Intelligence researchers through its Travel Grants for BSc and MSc students. The grants are designed to help students take their cutting-edge research beyond the lab and onto the global stage—presenting their works at the world’s leading AI and ML conferences.
Between 2024 and 2025, the ELLIS Amsterdam Travel Grants have enabled students to present at prestigious venues including the eighteenth European Conference on Computer Vision (ECCV 2024), the thirty-eighth Conference on Neural Information Processing Systems (NeurIPS 2024), the twelfth and thirteenth International Conference on Learning Representations (ICLR 2024 and 2025), the forty-first and forty-second International Conference on Machine Learning (ICML 2024 and 2025), and the forty-first Conference on Uncertainty in Artificial Intelligence (UAI 2025).
In 2023, four travel grants were awarded to MSc students who published at the seventeeth Conference of the European Chapter of the Association for Computational Linguistics (EACL 2023), the sixty-first Annual Meeting of the Association for Computational Linguistics (ACL 2023), the Fortieth International Conference on Machine Learning (ICML 2023), the twenty-sixth International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI 2023). These conferences are key venues in AI/ML research, the forefront of innovation, and participation at the top-tier conferences not only amplifies the impact of the students’ research but also connects them with the wider research community.
By enabling young researchers to showcase their work at international conferences, the unit encourages the development of high-quality research locally and provides research exposure and recognition, as Amsterdam’s growing contribution to the European and global AI landscapes.
The unit also notes that several of the research projects being presented are the result of cross-border collaboration within the wider ELLIS Society network, made possible by, among others, the ELLIS unit Amsterdam’s MSc Honours Programme, which features co-supervision by two ELLIS Members in different countries. This underscores the collaborative spirit that ELLIS champions: pushing the boundaries of AI research through shared knowledge and international teamwork.
The grants are currently awarded to students whose papers are accepted to the main tracks of top conferences, ensuring the highest standards of research are maintained. The travel grant initiative serves a dual purpose: celebrating local academic excellence and showcasing Amsterdam’s thriving AI ecosystem to the world.
The UvA BSc and MSc Students who are interested in applying can find detailed information about the eligibility criteria and application process of the ELLIS unit Amsterdam’s Travel Grants, which is fully funded by the University of Amsterdam.
We highlight ten main track papers funded by the ELLIS unit Amsterdam travel grants in 2024-2025, as follows (in chronological order):
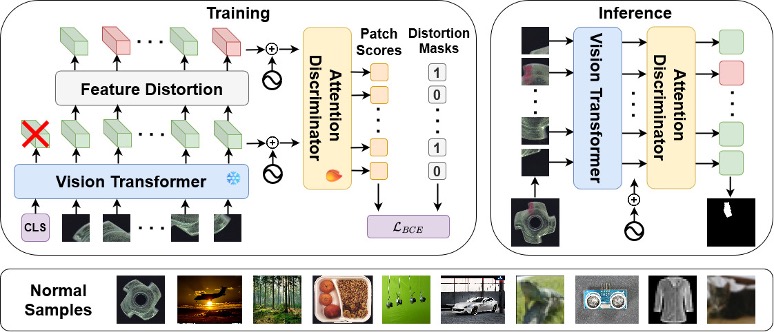
1. GeneralAD: Anomaly Detection Across Domains by Attending to Distorted Features
Authors- Luc P.J. Sträter, Mohammadreza Salehi, Efstratios Gavves, Cees G.M. Snoek, Yuki M. Asano
Conference- The Eighteenth European Conference on Computer Vision (ECCV 20224)
In the domain of anomaly detection, methods often excel in either high-level semantic or low-level industrial benchmarks, rarely achieving cross-domain proficiency. Semantic anomalies are novelties that differ in meaning from the training set, like unseen objects in self-driving cars. In contrast, industrial anomalies are subtle defects that preserve semantic meaning, such as cracks in airplane components. In this paper, we present GeneralAD, an anomaly detection framework designed to operate in semantic, near-distribution, and industrial settings with minimal per-task adjustments. In our approach, we capitalize on the inherent design of Vision Transformers, which are trained on image patches, thereby ensuring that the last hidden states retain a patch-based structure. We propose a novel self-supervised anomaly generation module that employs straightforward operations like noise addition and shuffling to patch features to construct pseudo-abnormal samples. These features are fed to an attention-based discriminator, which is trained to score every patch in the image. With this, our method can both accurately identify anomalies at the image level and also generate interpretable anomaly maps. We extensively evaluated our approach on ten datasets, achieving state-of-the-art results in six and on-par performance in the remaining for both localization and detection tasks.
2. No Train, all Gain: Self-Supervised Gradients Improve Deep Frozen Representations
Authors – Walter Simoncini, Andrei Bursuc, Spyros Gidaris, Yuki M. Asano
Conference – The Thirty-Eighth Conference on Neural Information Processing Systems (NeurIPS 2024)
Summary – this paper introduces FUNGI, Features from UNsupervised GradIents, a method to enhance the features of transformer encoders by leveraging self-supervised gradients. Our method is simple: given any pretrained model, we first compute gradients from various self-supervised objectives for each input. These gradients are projected to a lower dimension and then concatenated with the model’s output embedding. The resulting features are evaluated on k-nearest neighbor classification over 11 datasets from vision, 5 from natural language processing, and 2 from audio. Across backbones spanning various sizes and pretraining strategies, FUNGI features provide consistent performance improvements over the embeddings. We also show that using FUNGI features can benefit linear classification, clustering and image retrieval, and that they significantly improve the retrieval-based in-context scene understanding abilities of pretrained models, for example improving upon DINO by +17% for semantic segmentation – without any training. We propose using self-supervised gradients to enhance pretrained embedding features and achieve significant improvements in k-nearest neighbor classification, in-context learning, linear probing and clustering, across images, text and audio.
(i) Given a transformer backbone, e.g. a vision transformer (ViT), we forward an image or its views/patches (1), compute a self-supervised loss, e.g. SimCLR, and backpropagate (2). We then extract gradients with respect to the weights of a linear layer and project them (3, 4).
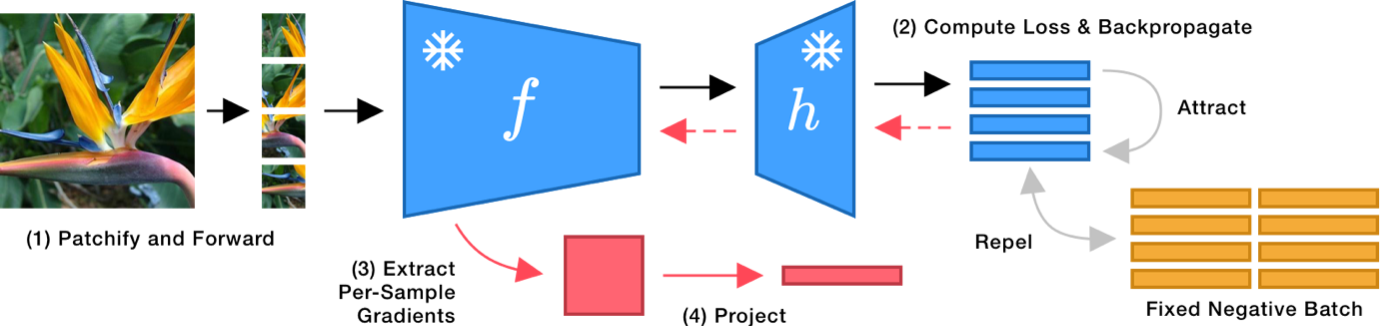
(ii) We call these FUNGI (Features from UNsupervised GradIents). They can be used as-is or combined with FUNGIs from other SSL losses or the model embeddings.
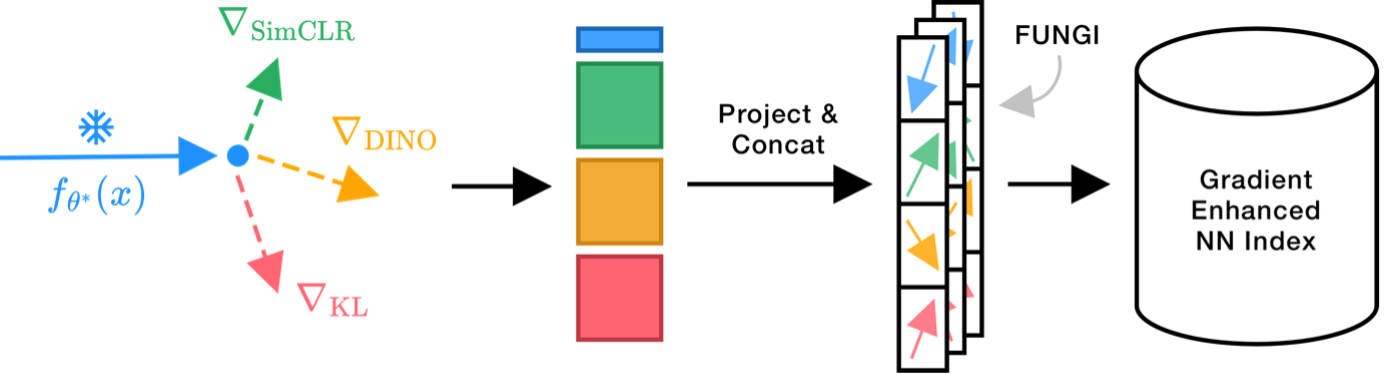
(iii) These features can be used for multiple tasks (retrieval, linear classification, clustering). E.g. in retrieval, our features improve k-nn classification for several backbones (on average across 11 vision datasets), especially in few-shot setups.
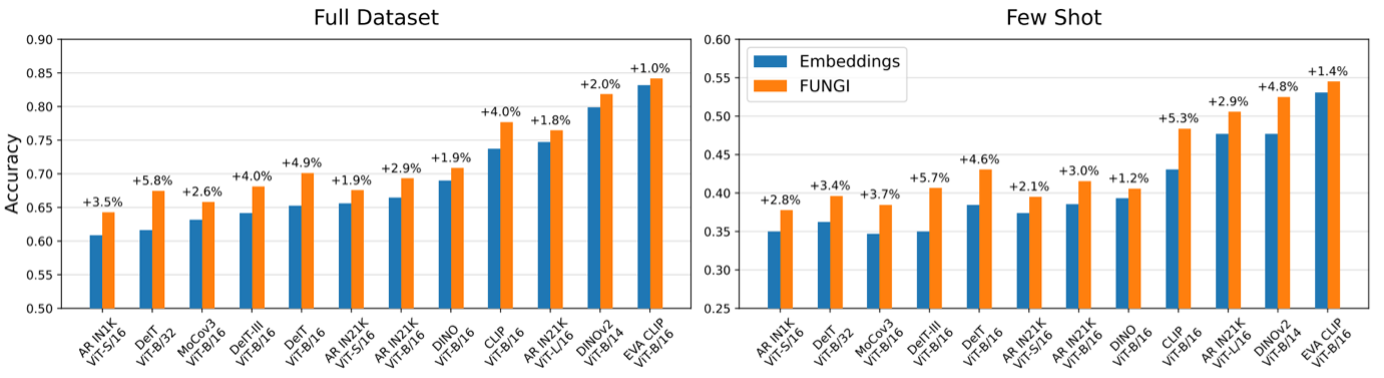
(iv) They can also improve in-context semantic segmentation, producing sharper and denser masks, even for complex objects such as horses and trains.

(v) Where GT stands for Ground Truth, and DINO is the baseline. While the experiments illustrated above are for vision, the findings also extend to language and audio.

3. VeRA: Vector-based Random Matrix Adaptation
Authors- Dawid J. Kopiczko, Tijmen Blankevoort, Yuki M. Asano
Conference- The Twelfth International Conference on Learning Representations (ICLR 2024)
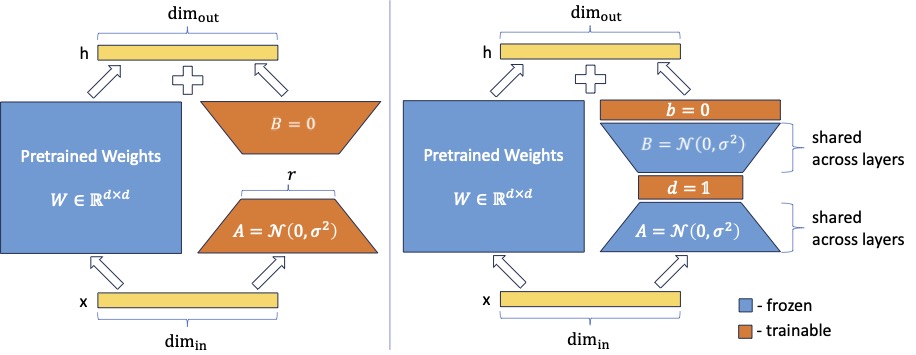
Summary- Low-rank adapation (LoRA) is a popular method that reduces the number of trainable parameters when finetuning large language models, but still faces acute storage challenges when scaling to even larger models or deploying numerous per-user or per-task adapted models. In this work, we present Vector-based Random Matrix Adaptation (VeRA), which significantly reduces the number of trainable parameters compared to LoRA, yet maintains the same performance. It achieves this by using a single pair of low-rank matrices shared across all layers and learning small scaling vectors instead. We demonstrate its effectiveness on the GLUE and E2E benchmarks, image classification tasks, and show its application in instruction-tuning of 7B and 13B language models.
4. A Probabilistic Approach To Learning the Degree of Equivariance in Steerable CNNs
Authors- Lars Veefkind and Gabriele Cesa
Conference- The Forty-First International Conference on Machine Learning (ICML 2024)
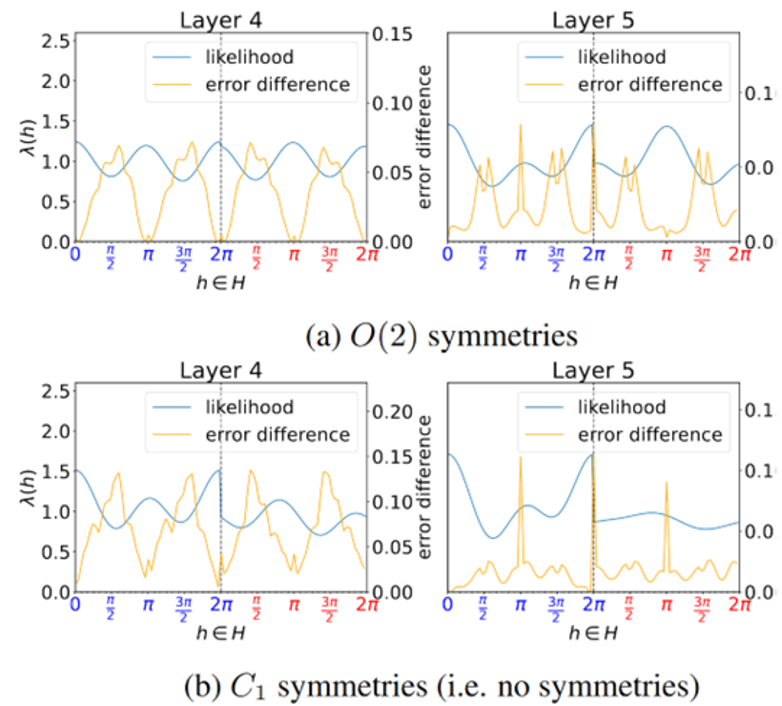
Summary- Steerable convolutional neural networks (SCNNs) enhance task performance by modelling geometric symmetries through equivariance constraints on weights. Yet, unknown or varying symmetries can lead to overconstrained weights and decreased performance. To address this, this paper introduces a probabilistic method to learn the degree of equivariance in SCNNs. We parameterise the degree of equivariance as a likelihood distribution over the transformation group using Fourier coefficients, offering the option to model layer-wise and shared equivariance. These likelihood distributions are regularised to ensure an interpretable degree of equivariance across the network. Advantages include the applicability to many types of equivariant networks through the flexible framework of SCNNs and the ability to learn equivariance with respect to any subgroup of any compact group without requiring additional layers. Our experiments reveal competitive performance on datasets with mixed symmetries, with learnt likelihood distributions that are representative of the underlying degree of equivariance.
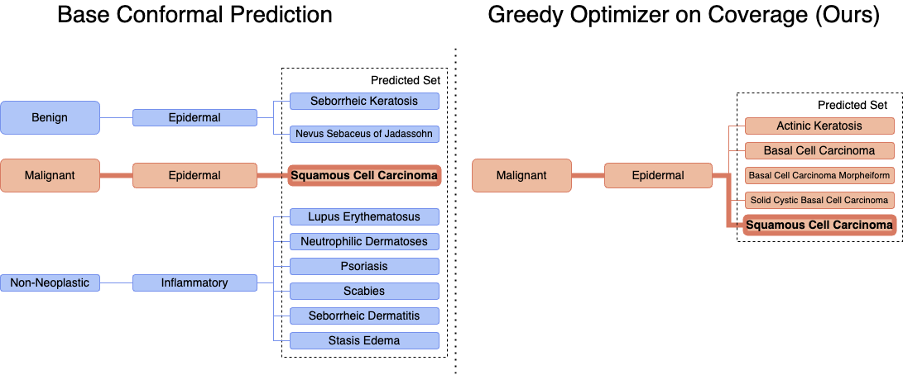
5. Utility-Directed Conformal Prediction: A Decision-Aware Framework for Actionable Uncertainty Quantification
Authors – Santiago Cortes-Gomez, Carlos Patiño, Yewon Byun, Steven Wu, Eric Horvitz, Bryan Wilder
Conference – The Thirteenth International Conference on Learning Representations (ICLR 2025)
Summary – This paper introduces a novel approach to conformal prediction that integrates downstream utility functions, improving decision-making in high-stakes domains. Traditional conformal predictors provide statistical coverage guarantees but lack alignment with specific decision objectives. This work bridges this gap by proposing methods to generate prediction sets that minimize user-defined cost functions while maintaining coverage guarantees. The main result is on a dataset for detecting skin diseases, where the proposed methods are more useful than standard conformal prediction because their predictions do not mix benign and malignant diagnoses.
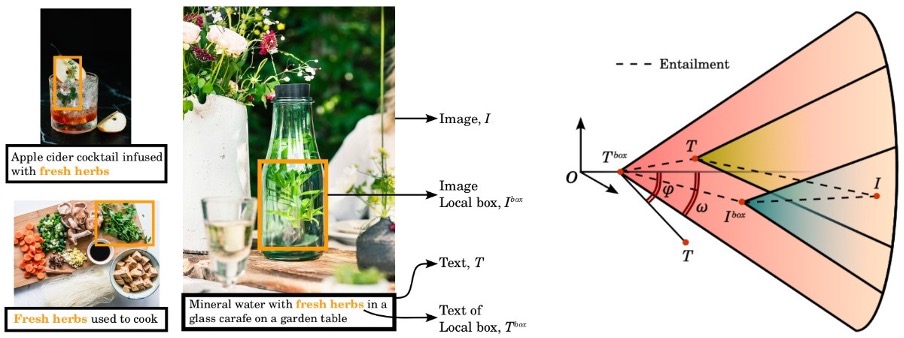
6. Compositional Entailment Learning for Hyperbolic Vision-Language Models
Authors – Avik Pal, Max van Spengler, Guido Maria D’Amely di Melendugno, Alessandro Flaborea, Fabio Galasso, Pascal Mettes
Conference – The Thirteenth International Conference on Learning Representations (ICLR 2025)
Summary – Images and texts are naturally hierarchical. This work proposes Compositional Entailment Learning for hyperbolic vision-language models. The idea is that an image is not only described by a sentence but is a composition of multiple object boxes, each with its textual description. Such information can be obtained freely by extracting nouns from sentences and using openly available localized grounding models. This method hierarchically organizes images, image boxes, and textual descriptions through contrastive and entailment-based objectives. Empirical evaluation on a hyperbolic vision-language model trained with millions of image-text pairs shows that the proposed compositional learning approach outperforms conventional Euclidean CLIP learning, as well as recent hyperbolic alternatives, with better zero-shot and retrieval generalization and stronger hierarchical performance.
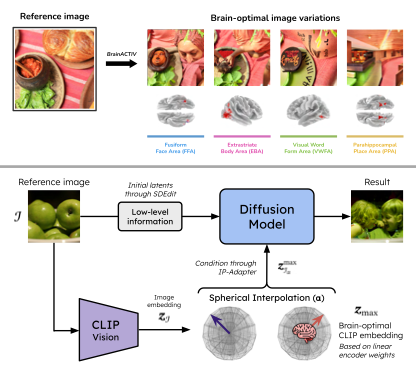
7. BrainACTIV: Identifying visuo-semantic properties driving cortical selectivity using diffusion-based image manipulation
Authors- Diego García Cerdas, Christina Sartzetaki, Magnus Petersen, Gemma Roig, Pascal Mettes, Iris Groen
Conference- The Thirteenth International Conference on Learning Representations (ICLR 2025)
Summary- The human brain efficiently represents visual inputs through specialized neural populations that selectively respond to specific categories. Brain Activation Control Through Image Variation (BrainACTIV) is a method for manipulating a reference image to enhance or decrease activity in a target cortical region using pretrained diffusion models. Starting from a reference image allows for fine-grained and reliable offline identification of optimal visuo-semantic properties, as well as producing controlled stimuli for novel neuroimaging studies.
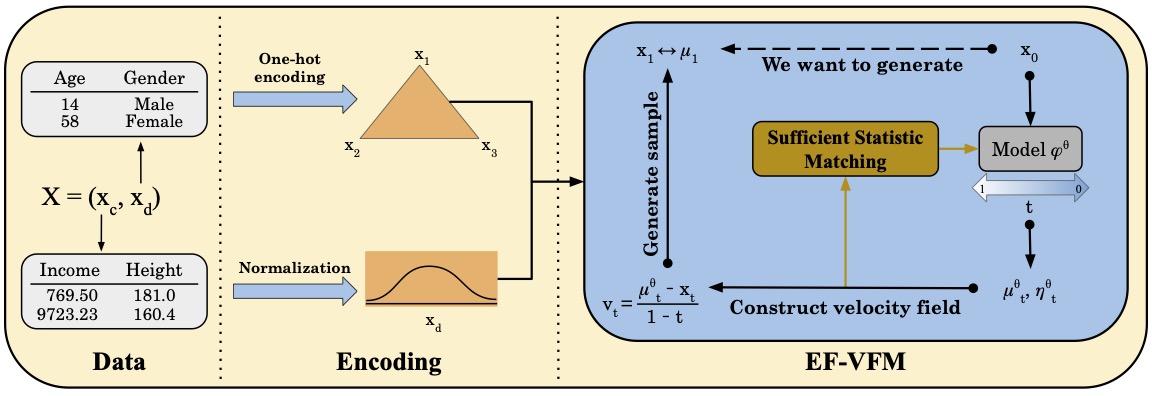
8. Exponential Family Variational Flow Matching for Tabular Data Generation
Authors- Andrés Guzmán-Cordero, Floor Eijkelboom and Jan-Willem van de Meent
Conference – The Forty-Second International Conference on Machine Learning (ICML 2025)
Summary- We extend variational flow matching by leveraging exponential family distributions to handle heterogeneous data types efficiently, and further show a prototype of this framework, TabbyFlow, to showcase its use in tabular data generation.
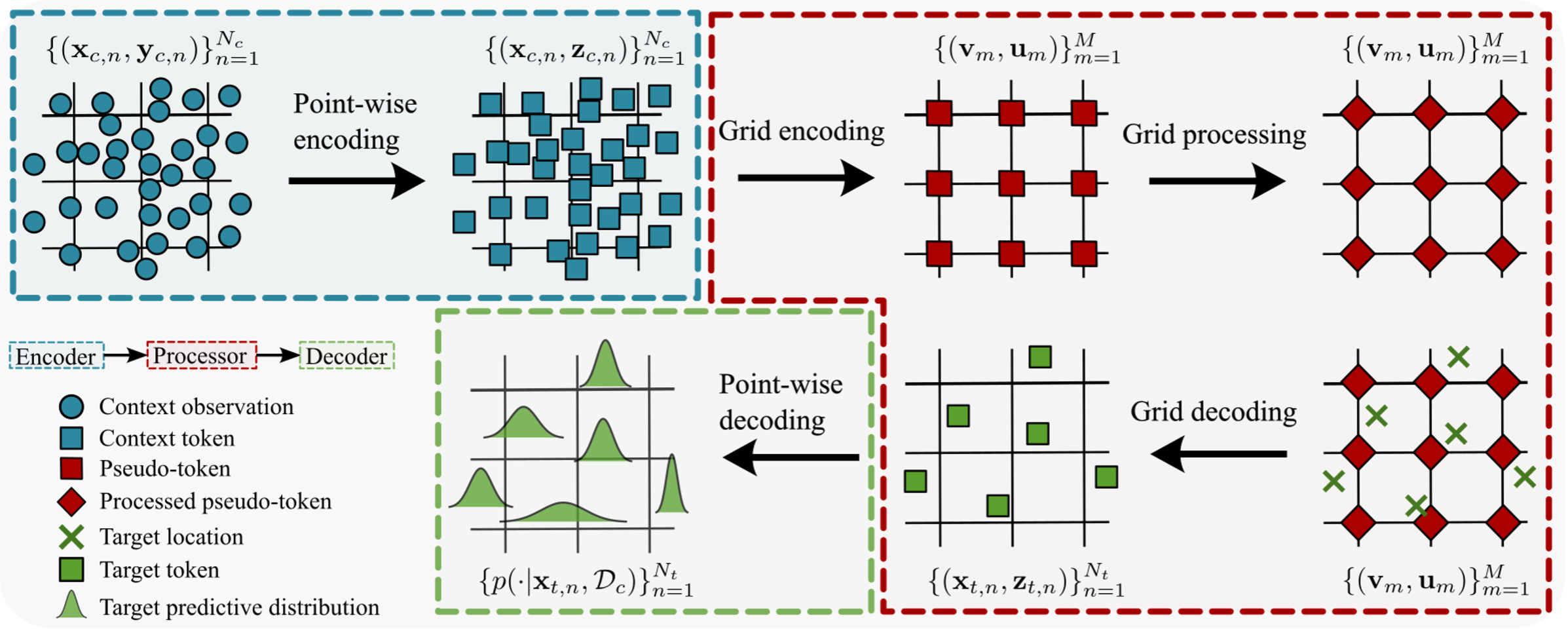
9. Gridded Transformer Neural Processes for Spatio-Temporal Data
Authors – Matthew Ashman*, Cristiana Diaconu*, Eric Langezaal*, Adrian Weller, Richard Turner
Conference – The Forty-Second International Conference on Machine Learning (ICML 2025)
Summary – Effective modelling of large-scale spatio-temporal datasets is essential for many domains, yet existing approaches often impose rigid constraints on the input data, such as requiring them to lie on fixed-resolution grids. With the rise of foundation models, the ability to process diverse, heterogenous data structures is becoming increasingly important. Neural processes (NPs), particularly transformer neural processes (TNPs), offer a promising framework for such tasks, but struggle to scale to large spatio-temporal datasets due to the lack of an efficient attention mechanism. To address this, we introduce gridded pseudo-token TNPs which employ specialised encoders and decoders to handle unstructured data and utilise a processor comprising gridded pseudo-tokens with efficient attention mechanisms. Furthermore, we develop equivariant gridded TNPs for applications where exact or approximate translation equivariance is a useful inductive bias, improving accuracy and training efficiency. Our method consistently outperforms a range of strong baselines in various synthetic and real-world regression tasks involving large-scale data, while maintaining competitive computational efficiency. Experiments with weather data highlight the potential of gridded TNPs and serve as just one example of a domain where they can have a significant impact.
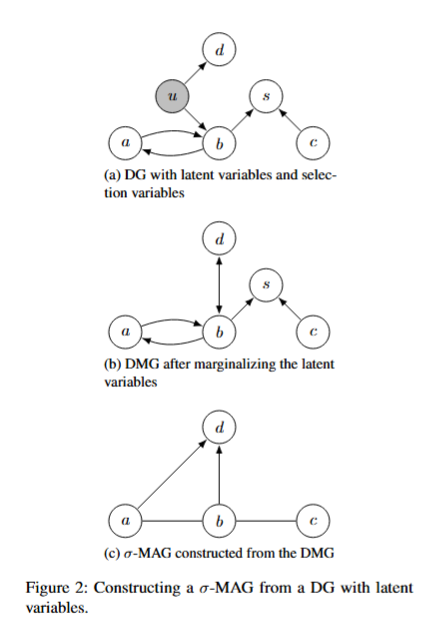
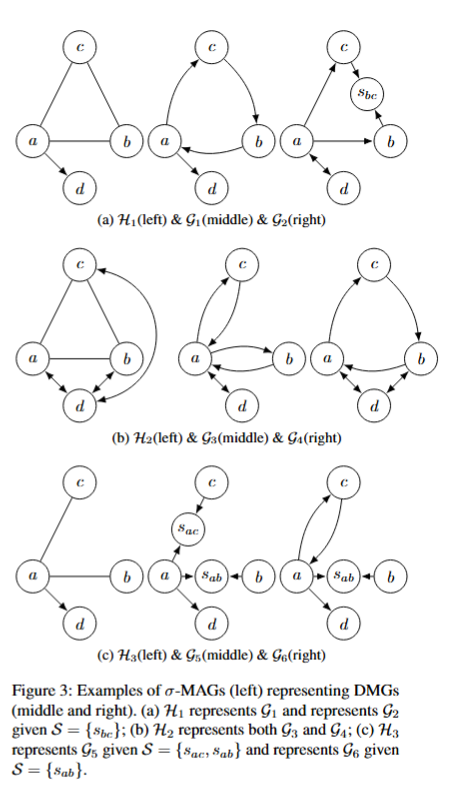
10. $\sigma$-Maximal Ancestral Graphs
Authors-Binghua Yao, Joris M. Mooij
Conference- The Forty-first Conference on Uncertainty in Artificial Intelligence (UAI 2025)
Summary- Graphs—networks of nodes connected by edges—are a powerful tool for understanding relationships between variables. In many fields such as biology, economics, and computer science, we use causal graphs to represent how one variable can influence another. A commonly used type of graph for this is called a DAG (Directed Acyclic Graph), where arrows represent cause-and-effect, and cycles (like feedback loops) are not allowed.
However, real-world systems often include hidden (latent) variables and selection bias, and may even involve feedback—like when a system’s output affects its input. To represent such systems abstractly, researchers use more general graphs called MAGs (Maximal Ancestral Graphs). These are great for modeling hidden variables, but they cannot handle cycles, limiting their use in more complex situations.
In this thesis, we fix that limitation. We introduce a new kind of graph, called a $\sigma$-MAG ($\sigma$-Maximal Ancestral Graph), which can represent cyclic causal systems while still accounting for hidden variables. These new graphs generalize MAGs and make it possible to model more realistic systems where feedback and information flow matter.
We also study the mathematical properties of these new graphs—such as when two different graphs actually represent the same system (this is called Markov equivalence)—and lay the groundwork for using them in future algorithms for discovering causal relationships from data.