Background no more: Action recognition across domains by causal interventions
Abstract
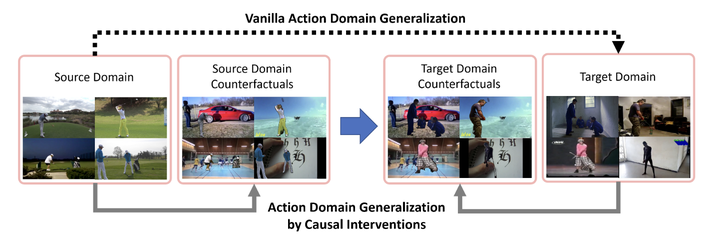
We aim to recognize actions under an appearance distribution shift between a source training domain and a target test domain. To enable such video domain generalization, our key idea is to intervene on the action to remove the confounding effect of the domain background on the class label using causal inference. Towards this, we propose to learn a causally debiased model on a source domain that intervenes on the action through three possible Do-operators, which separate the action and background. To better align the source and target distributions, we also introduce a test-time action intervention. Experiments on two challenging video domain generalization benchmarks reveal that causal inference is a promising tool for action recognition as it already achieves state-of-the-art results on Kinetics2Mimetics, the benchmark with the largest domain shift.