Counterfactual attribute-based visual explanations for classification
Abstract
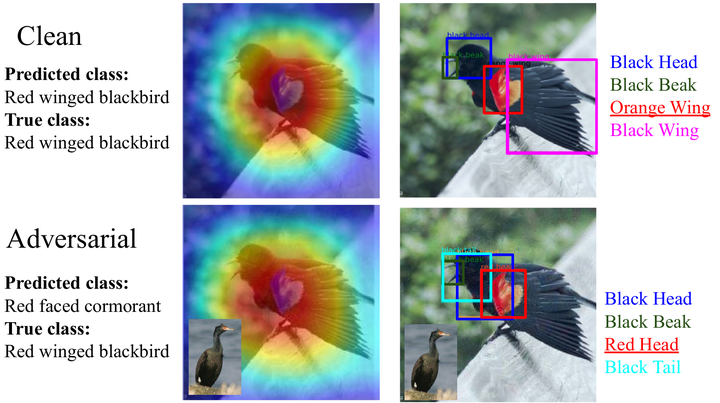
In this paper, our aim is to provide human understandable intuitive factual and counterfactual explanations for the decisions of neural networks. Humans tend to reinforce their decisions by providing attributes and counterattributes. Hence, in this work, we utilize attributes as well as examples to provide explanations. In order to provide counterexplanations we make use of directed perturbations to arrive at the counterclass attribute values in doing so, we explain what is present and what is absent in the original image. We evaluate our method when images are misclassified into closer counterclasses as well as when misclassified into completely different counterclasses. We conducted experiments on both finegrained as well as coarsegrained datasets. We verified our attribute-based explanations method both quantitatively and qualitatively and showed that attributes provide discriminating and human understandable explanations for both standard as well as robust networks.