Intriguing Properties of Hyperbolic Embeddings in Vision-Language Models
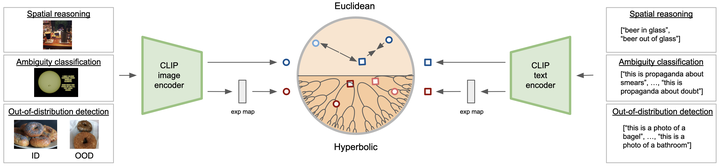
Abstract
Vision-language models have in short time been established as powerful networks, demonstrating strong performance on a wide range of downstream tasks. A key factor behind their success is the learning of a joint embedding space where pairs of images and textual descriptions are contrastively aligned. Recent work has explored the geometry of the joint embedding space, finding that hyperbolic embeddings provide a compelling alternative to the commonly used Euclidean embeddings. Specifically, hyperbolic embeddings yield improved zero-shot generalization, better visual recognition, and more consistent semantic interpretations. In this paper, we conduct a deeper study into the hyperbolic embeddings and find that they open new doors for vision-language models. In particular, we find that hyperbolic vision-language models provide spatial awareness that Euclidean vision-language models lack, are better capable of dealing with ambiguity, and effectively discriminate between distributions. Our findings shed light on the greater potential of hyperbolic embeddings in large-scale settings, reaching beyond conventional downstream tasks. Our code is available at https://github.com/saibr/hypvl