Object Priors for Classifying and Localizing Unseen Actions
Abstract
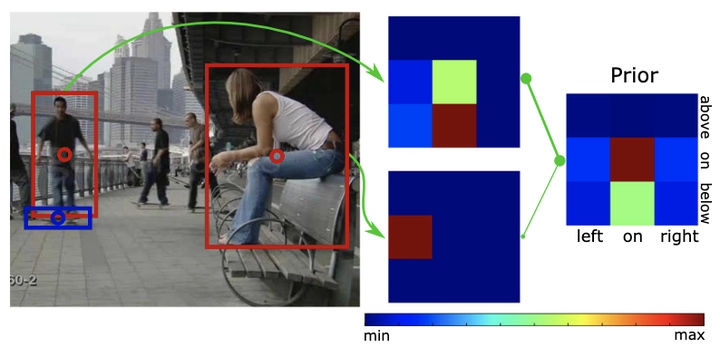
This work strives for the classification and localization of human actions in videos, without the need for any labeled video training examples. Where existing work relies on transferring global attribute or object information from seen to unseen action videos, we seek to classify and spatio-temporally localize unseen actions in videos from image-based object information only. We propose three spatial object priors, which encode local person and object detectors along with their spatial relations. On top we introduce three semantic object priors, which extend semantic matching through word embeddings with three simple functions that tackle semantic ambiguity, object discrimination, and object naming. A video embedding combines the spatial and semantic object priors. It enables us to introduce a new video retrieval task that retrieves action tubes in video collections based on user-specified objects, spatial relations, and object size. Experimental evaluation on five action datasets shows the importance of spatial and semantic object priors for unseen actions. We find that persons and objects have preferred spatial relations that benefit unseen action localization, while using multiple languages and simple object filtering directly improves semantic matching, leading to state-of-the-art results for both unseen action classification and localization.