Are 3D convolutional networks inherently biased towards appearance?
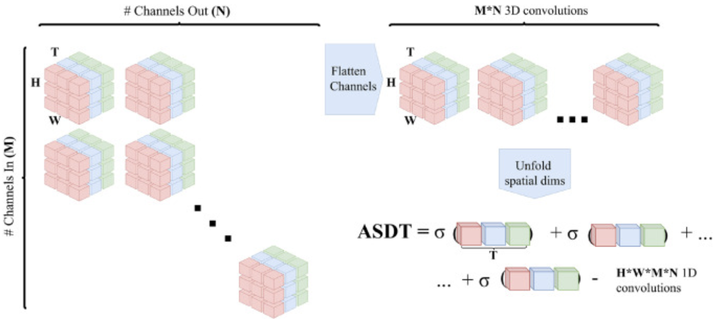
Abstract
3D convolutional networks, as direct inheritors of 2D convolutional networks for images, have placed their mark on action recognition in videos. Combined with pretraining on large-scale video data, high classification accuracies have been obtained on numerous video benchmarks. In an effort to better understand why 3D convolutional networks are so effective, several works have highlighted their bias towards static appearance and towards the scenes in which actions occur. In this work, we seek to find the source of this bias and question whether the observed biases towards static appearances are inherent to 3D convolutional networks or represent limited significance of motion in the training data. We resolve this by presenting temporality measures that estimate the data-to-model motion dependency at both the layer-level and the kernel-level. Moreover, we introduce two synthetic datasets where motion and appearance are decoupled by design, which allows us to directly observe their effects on the networks. Our analysis shows that 3D architectures are not inherently biased towards appearance. When trained on the most prevalent video sets, 3D convolutional networks are indeed biased throughout, especially in the final layers of the network. However, when training on data with motions and appearances explicitly decoupled and balanced, such networks adapt to varying levels of temporality. To this end, we see the proposed measures as a reliable method to estimate motion relevance for activity classification in datasets and use them to uncover the differences between popular pre-training video collections, such as Kinetics, IG-65M and Howto100 m.