Accuracy of deep learning-based AI models for early caries lesion detection: the influence of annotation quality and reference choice
Abstract
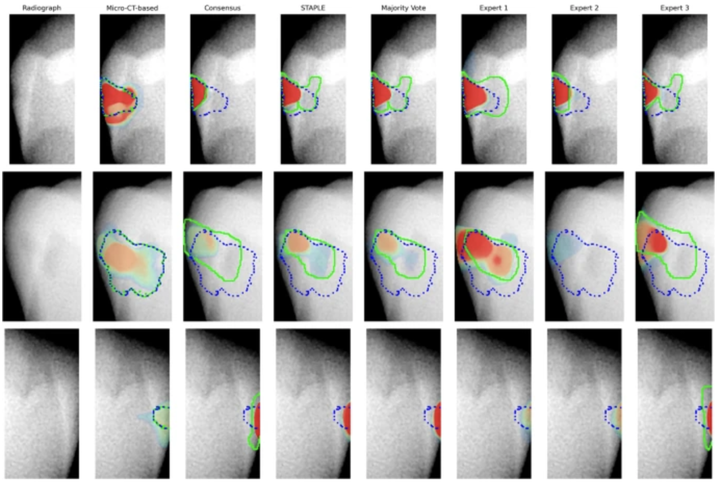
Objectives The objective of this study is to assess how different annotation methods used during AI model training affect the accuracy of early caries lesion detection, and how the choice of the evaluation reference standard leads to significant differences in assessing AI models’ outcomes. Clinical Relevance. AI-based tools for caries detection are becoming common in dentistry. This study shows that how these models are evaluated can significantly impact perceived performance. Clinicians and developers should ensure that evaluation standards are independent and clinically relevant to avoid overestimating AI’s diagnostic abilities and to build trust for real-world use and regulatory approval. Methods Multiple AI caries lesion segmentation models were trained on the ACTA-DIRECT dataset using annotations from (1) single dentists, (2) aggregated strategies (majority vote, consensus meetings, STAPLE), and (3) micro-CT-based methods. Model accuracy was evaluated using two approaches: (1) comparison against micro-CT-based annotations and (2) comparison against the training-matched annotations. Statistical significance of differences in model diagnostic accuracy across annotation strategies was assessed using the McNemar test. Results There was no statistically significant difference in diagnostic accuracy among AI models when compared to micro-CT-based annotations. However, the diagnostic accuracy was considered statistically significantly higher when the results of the AI models were evaluated with the training-matched annotations. Conclusion Our findings indicate a strong influence of reference standards on AI model evaluation. While annotation strategies during training did not significantly affect AI accuracy in caries lesion segmentation, evaluation was subject to bias when models were tested against different reference standards. Clinical relevance AI-based tools for caries detection are becoming common in dentistry. This study shows that how these models are evaluated can significantly impact perceived performance. Clinicians and developers should ensure that evaluation standards are independent and clinically relevant to avoid overestimating AI’s diagnostic abilities and to build trust for real-world use and regulatory approval.