MediaMill Datasets
MediaMill VideoStory
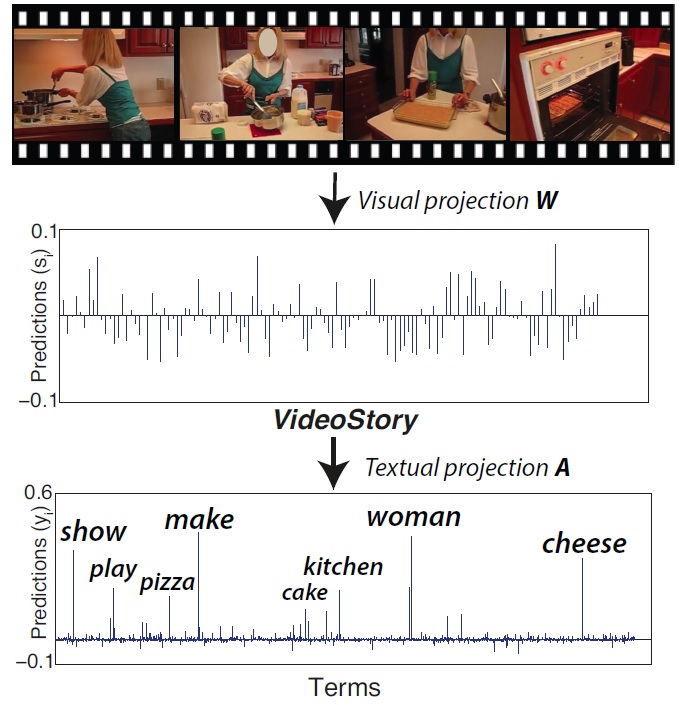
VideoStory learns an embedding from videos and their descriptions for few-example recognition and translation of videos. We train our embedding from web data by optimizing both the visual projection accuracy for recognition and the textual projection completeness for translation. For unseen videos it recognizes the event category from few examples and it predicts the most likely description from visual content only.
VideoStory46K dataset
The dataset contains 45,826 videos and their descriptions obtained by harvesting YouTube. The videos have an average length of 58.4 seconds and the whole collection contains 743 hours of videos. Every video comes with a short title caption provided by the user who has uploaded the video.

- Download list of video URLs
- Download textual descriptions
- Plain text [post processed by removing stop words and a simple stemming]
- Term vectors + dictionary in matlab
- Download video features [Fisher vector encoding of MBH descriptors by Wang and Schmid, ICCV 2013]
TRECVID MED 2013
To make our experiments repeatable, we provide our extracted features on the TRECVID MED 2013 dataset.
- Download train video features + video names
- Download test video features + video names
Below we show a table with the results for MEDtest 2013 using the 10Ex and 100Ex condition, for the MBH features by Wang and Schmid as baseline and when learning VideoStory on top.
| Method | 10Ex | 100Ex |
|---|---|---|
| MBH | 17.4 | 31.5 |
| VideoStory | 19.6 | 32.0 |
Download Code + Data
Including the whole data and code required to perform event recognition by VideoStoryContact
If you have any question please contact Amirhossein Habibian at a.habibian@uva.nl.
Readme First
Amirhossein Habibian, Thomas Mensink, and Cees G.M. Snoek. VideoStory: A New Multimedia Embedding for Few-Example Recognition and Translation of Events. In Proceedings of the ACM International Conference on Multimedia, pp. 17-26, Orlando, USA, November 2014.