Data Set
Systematic Evaluation
The purpose of the challenge problem for generic video indexing is to provide researchers with a framework for the systematic evaluation of video indexing components. To allow for systematic evaluation, we organize the challenge problem as a laboratory test. In such a test the variability stemming from multimedia data, concepts, experiments, and performance must be structured to allow for comparison of results. To arrive at a laboratory test for the challenge problem, we separate a multimedia archive in a training set and a test set, using camera shots as the unit for indexing and evaluation, in line with the common procedure in literature. For each set, we provide manually labeled ground truth, at the shot level, in the form of a shared concept lexicon. We define a set of experiments which index shots in the test set based on algorithms tuned on the training set. For each concept in the lexicon this should yield a list of shots, ranked according to detector confidence of concept presence. To evaluate these ranked lists we use average precision.
Multimedia Data Download
The Challenge Problem uses 85 hours of video data from the 2005 NIST TRECVID benchmark (i.e. the TRECVID 2005 training set), containing Arabic, Chinese, and US broadcast news sources, recorded in MPEG-1 during November 2004 by the Linguistic Data Consortium.
Download
If you want to do visual and/or textual feature extraction, and you have not
participated in TRECVID 2005 or 2006, the TRECVID data (black hyperlinks)
is required.
![]() Video data (Available for fee from LDC, soon)
Video data (Available for fee from LDC, soon)
![]() Key frames & Transcripts (Available for fee from LDC)
Key frames & Transcripts (Available for fee from LDC)
![]() Master Shot Boundaries by Fraunhofer Institute (Available for free from NIST)
Master Shot Boundaries by Fraunhofer Institute (Available for free from NIST)
![]() Automatic Speech Recogntion/Machine Translation output (Available for free from NIST)
Automatic Speech Recogntion/Machine Translation output (Available for free from NIST)
All MediaMill data -- containing groundtruth, features, classifier models, output, and performance --
are available in a 5.21GB tarball. Due to the size, downloading via a browser
might be problematic. However, wget
with the --ignore-length option should do the trick.
This command works on a modern linux machine:
wget -nv --ignore-length http://isis-data.science.uva.nl/cgmsnoek/mediamill/mediamill-challenge.tar.gz
After download, please verify that the MD5 checksum of the file is:
MD5(mediamill-challenge.tar.gz)=9a61dd05c99f8b0e5d0a22f41f3e078d.
Note that the shot-id from the TRECVID master shot boundaries is the fundamental unit for indexing.
Annotated Concept Lexicon
We detect in this archive a lexicon of 101 semantic concepts. For the manually annotated examples, we rely, in part,
on the TRECVID
2005 common annotation effort, which annotated
39 concepts.
We extended it to 101 concept annotations.

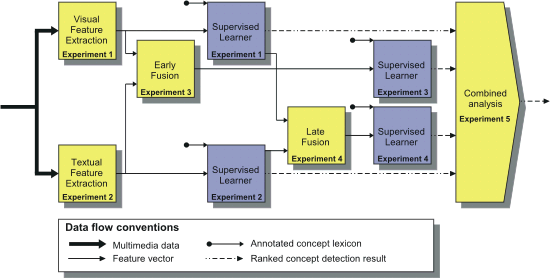
Experiments Data Flow
Data flow within the proposed challenge problem for
generic video indexing of 101 semantic concepts. Experiment 1 and
2 focus on unimodal analysis, yielding a visual and a textual
concept classification. Experiment 3 and 4 employ an early and
late fusion scheme respectively. The challenge problem allows for
the construction of four classifiers for each concept. In
experiment 5, an optimum is selected based on combined analysis.
Readme First
Cees G.M. Snoek, Marcel Worring, Jan C. van Gemert, Jan-Mark Geusebroek, and Arnold W.M. Smeulders. The Challenge Problem for Automated Detection of 101 Semantic Concepts in Multimedia. In Proceedings of ACM Multimedia, pp. 421-430, Santa Barbara, USA, October 2006.