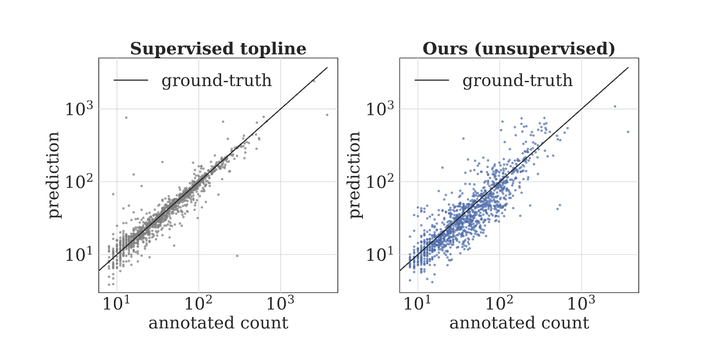
Abstract
While recent supervised methods for reference-based object counting continue to improve the performance on benchmark datasets, they have to rely on small datasets due to the cost associated with manually annotating dozens of objects in images. We propose UnCounTR, a model that can learn this task without requiring any manual annotations. To this end, we construct ‘Self-Collages’, images with various pasted objects as training samples, that provide a rich learning signal covering arbitrary object types and counts. Our method builds on existing unsupervised representations and segmentation techniques to successfully demonstrate for the first time the ability of reference-based counting without manual supervision. Our experiments show that our method not only outperforms simple baselines and generic models such as FasterRCNN and DETR, but also matches the performance of supervised counting models in some domains.