A Unified Survey on Anomaly, Novelty, Open-Set, and Out-of-Distribution Detection: Solutions and Future Challenges
Abstract
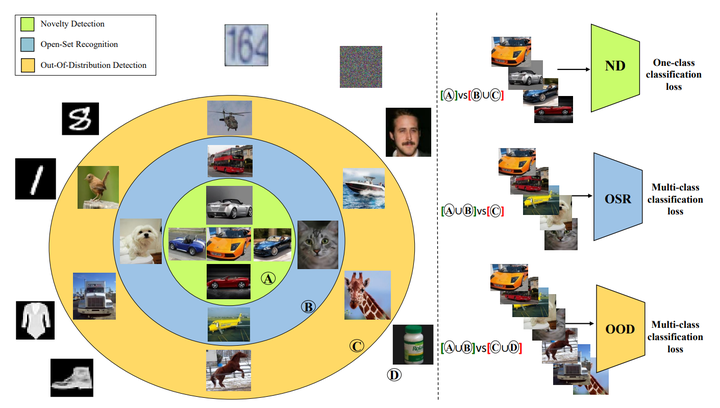
Machine learning models often encounter samples that are diverged from the training distribution. Failure to recognize an out-of-distribution (OOD) sample, and consequently assign that sample to an in-class label, significantly compromises the reliability of a model. The problem has gained significant attention due to its importance for safety deploying models in open-world settings. Detecting OOD samples is challenging due to the intractability of modeling all possible unknown distributions. To date, several research domains tackle the problem of detecting unfamiliar samples, including anomaly detection, novelty detection, one-class learning, open set recognition, and out-of-distribution detection. Despite having similar and shared concepts, out-of-distribution, open-set, and anomaly detection have been investigated independently. Accordingly, these research avenues have not cross-pollinated, creating research barriers. While some surveys intend to provide an overview of these approaches, they seem to only focus on a specific domain without examining the relationship between different domains. This survey aims to provide a cross domain and comprehensive review of numerous eminent works in respective areas while identifying their commonalities. Researchers can benefit from the overview of research advances in different fields and develop future methodology synergistically. Furthermore, to the best of our knowledge, while there are surveys in anomaly detection or one-class learning, there is no comprehensive or up-todate survey on out-of-distribution detection, which this survey covers extensively. Finally, having a unified cross-domain perspective, this study discusses and sheds light on future lines of research, intending to bring these fields closer together