R-MAE: Regions Meet Masked Autoencoders
Abstract
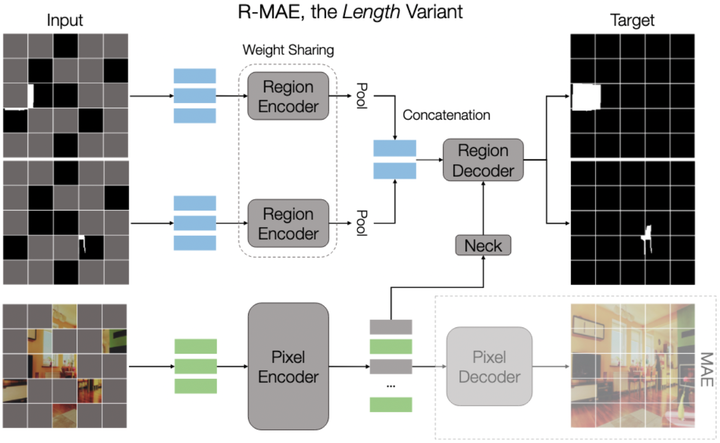
In this work, we explore regions as a potential visual analogue of words for self-supervised image representation learning. Inspired by Masked Autoencoding (MAE), a generative pre-training baseline, we propose masked region autoencoding to learn from groups of pixels or regions. Specifically, we design an architecture which efficiently addresses the one-to-many mapping between images and regions, while being highly effective especially with high-quality regions. When integrated with MAE, our approach (R-MAE) demonstrates consistent improvements across various pre-training datasets and downstream detection and segmentation benchmarks, with negligible computational overheads. Beyond the quantitative evaluation, our analysis indicates the models pre-trained with masked region autoencoding unlock the potential for interactive segmentation.