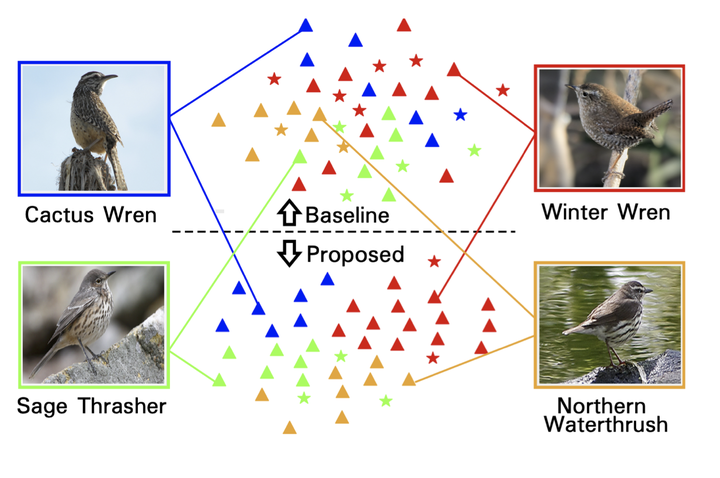
Abstract
Zero-shot learning strives to classify unseen categories for which no data is available during training. In the generalized variant, the test samples can further belong to seen or unseen categories. The state-of-the-art relies on Generative Adversarial Networks that synthesize unseen class features by leveraging class-specific semantic embeddings. During training, they generate semantically consistent features, but discard this constraint during feature synthesis and classification. We propose to enforce semantic consistency at all stages of (generalized) zero-shot learning: training, feature synthesis and classification. We further introduce a feedback loop, from a semantic embedding decoder, that iteratively refines the generated features during both the training and feature synthesis stages. The synthesized features together with their corresponding latent embeddings from the decoder are transformed into discriminative features and utilized during classification to reduce ambiguities among categories. Experiments on (generalized) zero-shot learning for object and action classification reveal the benefit of semantic consistency and iterative feedback, outperforming existing methods on six zero-shot learning benchmarks.