Abstract
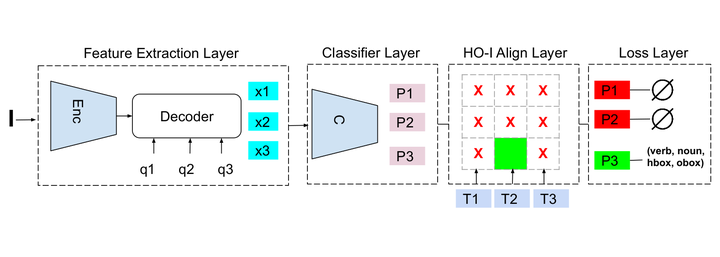
The goal of this paper is Human-object Interaction (HO-I) detection. HO-I detection aims to find interacting human-objects regions and classify their interaction from an image. Researchers obtain significant improvement in recent years by relying on strong HO-I alignment supervision from [5]. HO-I alignment supervision pairs humans with their interacted objects, and then aligns human-object pair(s) with their interaction categories. Since collecting such annotation is expensive, in this paper, we propose to detect HO-I without alignment supervision. We instead rely on image-level supervision that only enumerates existing interactions within the image without pointing where they happen. Our paper makes three contributions: i) We propose Align-Former, a visual-transformer based CNN that can detect HO-I with only image-level supervision. ii) Align-Former is equipped with HO-I align layer, that can learn to select appropriate targets to allow detector supervision. iii) We evaluate Align-Former on HICO-DET [5] and V-COCO [13], and show that Align-Former outperforms existing image-level supervised HO-I detectors by a large margin (4.71% mAP improvement from 16.14% to 20.85% on HICO-DET [5]).