Video Copy Detection Evaluation Showcase
Contact: Alexis Joly, INRIA Rocquencourt, Team IMEDIA, France.
Growing broadcasting of digital video content on different media brings
the search of copies in large video databases to a new critical issue.
Digital videos can be found on TV Channels, Web-TV, Video Blogs and the
public Video Web servers. The massive capacity of these sources makes
the tracing of video content into a very hard problem for video
professionals.
There are different ways for dealing with the copy detection challenge
and this evaluation showcase is the first benchmark initiative for
exploring and comparing them.
Data and Results
The corpus is available from INRIA.
The results are available here.
Set Up
Database: About 100 hours of
video materials comming from different sources: web video clips,
TV archives, movies. The videos
cover very large kind of programs: documentaries, movies, sports events, TV shows, etc. The videos have different bitrates, different resolutions
and different video format : mpeg1 and mpeg2. All these informations
will be given with the videos.
Types of Queries: The queries
will be clustered in two levels of difficulties corresponding to two different sub-tasks ST1 and ST2. Each participant can play in one or both subtasks.
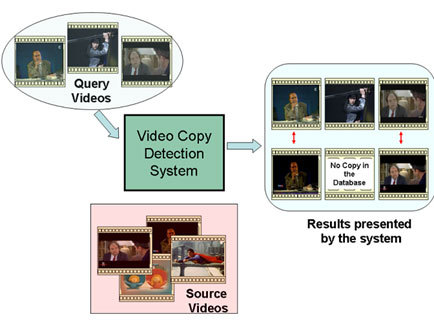
- Movie copies like queries (ST1):
Copies of entire long videos (from 5 minutes to 1 hour). The data can be reencoded, noised, or slightly retouched. Most difficult queries could be movies re-acquired by a cam-corder.
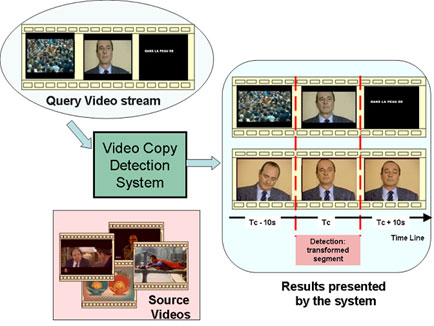
- TV stream like queries (ST2):
Several sequences will be choosen in the database and post-processed by professional audiovisual archivists with a professional video editing software.
Applied transformations can be very diversified: cropping; fade cuts; insertion of logos, borders, texts, moving texts, moving
characters, etc.; cholorimetric manipulations: contrast, gamma, etc.;
Queries include parts of several videos belonging or not to the database. Sequences belonging to the database must be identified and localized by their start and end time codes. The length of the inserted segment can be from 1 second to 1 minute.
Evaluation Metric
1. QUALITY metric
- Movie copies ST1:
a set of video is used as queries and each query return an answer: the
file is a copy of a video (or of a part of a video) in the
database or the file is not a copy.
The result files should contain as many lines as the number of video queries. Each line should be as following:
Where:
- <Query> is the name of the query video file
- <Ref> is the name of the corresponding reference video file in the database or "not_in_db" if no copy is found
The final criteria is the number of correct answers divided by the number of queries.
Quality = Ncorrect / Nqueries
Example result file: NameOfTheTeam_ST1.result
-
TV stream ST2: a set of simulated video stream is used as query (we call a video stream a
video which contains different segments of videos reauthored). The copy detection
system has to identify the video segments (ie the frames) from the stream which are
copies of a video or a part of the video in the database.
The result files for comparing the results of each system should
contain as many lines as detected segment with every line as following:
| <Query> |
TcIn |
TcOut |
<Ref> |
TcRef
|
- <Query> is the name of the query video file
- TcIn is the beginning time code of the detection in the query video
- TcOut is the end time code of the detection in the query video
- <Ref> is the name of the corresponding reference video file in the database
- TcRef is the beginning time code of the detection for the reference video
The final criteria is computed from the percentage of mismatched frames in all queries (due to either not detected segments, or imprecisions in the detection or false positives).
Quality = 1 - ( Nmis / Nframes )
Example result file:
NameOfTheTeam_ST2.result
2. SPEED metric
The speed of each system will be measured during the event, we will considerer the time needed for dealing with all the query videos in each sub-task.
Organization
Before the event:
The data (about 100~200 Go of videos) will be on a secure ftp server with
password for each candidate. IP adress of each candidate will be
required by e-mail soon. The data will be online for the beginning of
May. Example of queries for each task will also be available.
The "D" day":
The
participants must bring a computer with their video copy detection
system and all needed data. Internet access will not be
available.
The queries will be handed on a DVD (one for each sub-task) which contains a directory with all the query video files. The "searcher" designated by each team will then use the system to
find the copies, there is no pre-processing of
these videos before the "D" day.
When the system has finished to process the videos, a text file
with the results as described in the Evaluation Metric section has to
be put on a USB Key given by the organizers. The result file has to called: "NameOfTheTeam_ST1.result".
The time used for dealing with all the videos on a sub-task is measured
between the moment the DVD is given to the participant and the moment
the USB Key is given back to the organizer.
In a second step, another DVD containing the video
queries for ST2 is given to the participant and the whole protocol is
the same.
The comparing results will be given at the end of the
day (Quality and time needed for each sub-task). Every participant will
have the possibility to demonstrate the relevance of their systems in
front of the audience in live (with extra video queries if necessary).
Participation
If you would like to participate in the Vide Copy Detection Showcase, send an
email to
Alexis Joly.
Include a short description of the system in PDF format and formatted
using the camera-ready templates available at
http://www.acm.org/sigs/pubs/proceed/template.html,
possibly with a screenshot or short movie. The deadline for
registration is the
26th of April 2007.
Organizers
Alexis Joly,
INRIA Rocquencourt, IMEDIA Research Group, France
Julien Law-To,
INRIA Rocquencourt, IMEDIA Research Group, France
Nozha Boujemaa,
INRIA Rocquencourt, IMEDIA Research Group, France
Partners
IRT
Sponsor

The showcase events are sponsored by the MUSCLE Network of Excellence.